[Note] C++ Primer Plus
C++ 中应使用 const(而不是 #define)定义符号常量
- 能够明确指定类型
- 自带 static 特性,能够将定义限制在特定的函数或文件中(定义在头文件中被多个文件包含)
- 能够将 const 用于更复杂的类型(如数组和结构)
- C++ 中可以用 const 值来声明数组长度
面向过程与面向对象
面向对象编程与传统的过程性编程的区别在于,OOP强调的是在运行阶段(而不是编译阶段)进行决策。运行阶段指的是程序正在运行时,编译阶段指的是编译器将程序组合起来时。运行阶段决策就好比度假时,选择参观哪些景点取决于天气和当时的心情;而编译阶段决策更像不管在什么条件下,都坚持预先设定的日程安排。
变量声明与 new
通常,对于大型数据(如数组、字符串和结构),应使用new,这正是new的用武之地。例如,假设要编写一个程序,它是否需要数组取决于运行时用户提供的信息。如果通过声明来创建数组,则在程序被编译时将为它分配内存空间。不管程序最终是否使 用数组,数组都在那里,它占用了内存。在编译时给数组分配内存被称为静态联编(static binding),意味着数组是在编译时加入到程序中 的。但使用new时,如果在运行阶段需要数组,则创建它;如果不需要,则不创建。还可以在程序运行时选择数组的长度。这被称为动态联编(dynamic binding),意味着数组是在程序运行时创建的。这种数组叫作动态数组(dynamic array)。使用静态联编时,必须在编写程序时指定数组的长度;使用动态联编时,程序将在运行时确定数组的长度。
静态数组与动态数组
- 静态数组由声明产生
- 动态数组由 new 产生
- sizeof(静态数组) == 整个数组占用的空间大小
- sizeof(动态数组) == 数组指针占用的空间大小(对于 64 位系统即 8)
- 不能修改静态数组名
- 可以修改动态数组指针(比如自增)
数组指针和(&数组指针)的值不同
数组名和(&数组名)的值相同,但概念上又有区别(以 int 指针为例)
数组名代表(仅仅是代表,本身并不是指针类型)数组第一个元素的地址,可以将其赋值给 int* 类型
(数组名 + 1)指向下一个元素的地址
数组名[0]是数组第一个元素
(&数组名)是指向整个数组的指针(例如int (*)[10])(并不是二重指针 int** 类型)
(&数组名 + 1)指向整个数组后的元素的地址
(&数组名)[0] 不是数组第一个元素而是一个地址(与数组名和(&数组名)的值相同),*(&数组名)[0] 才是数组第一个元素
这部分可以参考 4.8 小节举的例子
指针与 const
如果数据类型本身并不是指针,则可以将 const 数据或非 const 数据的地址赋给指向 const 的指针,但只能将非 const 数据的地址赋给非 const 指针。
对于两级间接关系,则不允许将非 const 地址赋给 const 指针。如果允许:
1 | const int **pp2; |
上述代码将非 const 地址(&p1)赋给了 const 指针(pp2),导致可以通过 p1 来修改 const 数据,这显然是不安全的。
因此,仅当只有一层间接关系(如指针指向基本数据类型)时,才可以将非 const 地址或指针赋给 const 指针。
左值与右值
左值:可被引用的数据对象(常规变量和 const 变量),例如变量、数组元素、结构成员、引用和解除引用的指针
右值:不能通过地址访问的值,包括字面常量(用引号括起的字符串除外,它们由其地址表示)和包含多项的表达式(括号括起的单个变量不是右值)
右值引用:可指向右值,使用 && 声明
左值引用:使用 & 声明的引用
如果函数调用的参数不是左值或与相应的 const 引用参数的类型不匹配,则 C++ 将创建类型正确的匿名变量,将函数调用的参数的值传递给该匿名变量,并让参数来引用该变量。
函数模板的实例化与具体化
隐式实例化(Implicit Instantiation):根据调用函数时传入的参数类型生成函数定义
显式实例化(Explicit Instantiation):直接命令编译器创建特定的实例,其语法是:
1
template void Swap<int>(int &, int &);
还可通过在程序中使用函数来创建显式实例化,例如:
1
2
3
4
5
6
7
8
9template <class T>
T Add(T a, T b)
{
return a + b;
}
...
int m = 6;
double x = 10.2;
cout << Add<double>(x, m) << endl;这里的模板与函数调用
Add(x, m)不匹配,因为该模板要求两个函数参数的类型相同。但通过使用Add<double>(x, m),可强制为double类型实例化,并将参数m强制转换为double类型,以便与函数Add<double>(double, double)的第二个参数匹配。显式具体化(Explicit Specialization):专门为某类型显式地定义函数定义,其语法是:
1
2template <> void Swap<int>(int &, int &);
template <> void Swap(int &, int &);
隐式实例化、显式实例化、显式具体化统称为具体化,都表示使用具体类型的函数定义,而不是通用描述。具体化优先于常规模板,而非模板函数优先于具体化和常规模板。
注:不能在同一个文件(或转换单元)中使用同一种类型的显式实例化和显式具体化。
关键字 decltype
解决声明类型不确定的问题:
1 | template<class T1, class T2> |
多次声明,结合使用 typedef 和 decltype
:
1 | template<class T1, class T2> |
但无法直接用于声明函数返回类型,需结合关键字 auto 后置返回类型:
1 | template<class T1, class T2> |
类型推断规则(以 decltype(expr) var 为例):
- 若
expr是一个没有用括号括起的标识符,则var的类型与该标识符的类型相同(包括const等限定符),否则: - 若
expr是一个函数调用,则var的类型与函数的返回类型相同,否则: - 若
expr是一个左值,则var为指向其类型的引用,否则: var的类型与expr的类型相同。
头文件中常包含的内容
- 函数原型
- 使用
#define或const定义的符号常量 - 结构声明
- 类声明
- 模板声明
- 内联函数
存储连续性、作用域和链接性
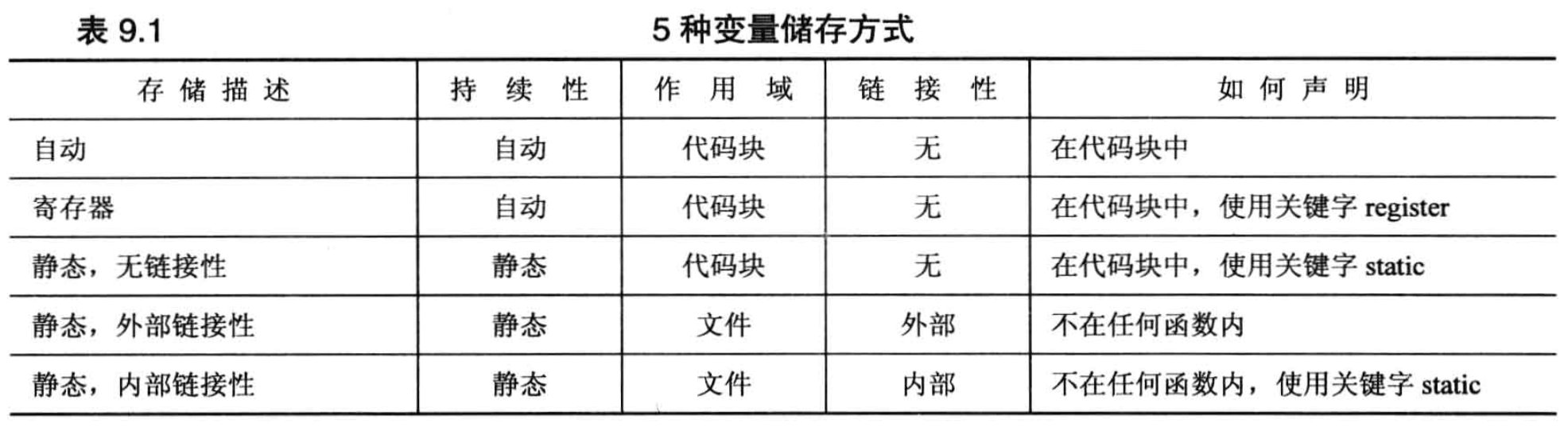
函数和链接性
- 存储持续性:静态,在整个程序执行期间都一直存在
- 默认链接性:外部,可以在文件间共享
- 在函数原型中使用关键字
extern来指出函数是在另一个文件中定义的(可选) - 使用关键字
static将函数的链接性设置为内部的(必须同时在原型和函数定义中使用该关键字) - 内联函数不受“单定义规则”的约束,因此可以将内联函数的定义放在头文件中
- 调用函数时编译器查找函数定义的步骤:
- 若文件中的函数原型指出该函数是静态的,则只在该文件中查找函数定义;
- 否则在所有程序文件中查找:
- 若找到两个定义,则发出错误消息;
- 若没有找到,则在库中搜索。
语言链接性
C 语言中一个名称只对应一个函数,而 C++ 中通过名称修饰为重载函数生成不同的符号名称,这就导致二者约定的内部函数名不一致。为解决这种问题,可以用函数原型来指出要使用的约定:
1 | extern "C" void spiff(int); // use C protocol for name look-up |
常规 new 与定位 new 运算符
- 常规
new运算符:在堆中找到一个足以能够满足要求的内存块 - 定位
new运算符:指定要使用的位置(可以是非堆区),基本只是返回传递给它的地址,并将其强制转换为void *,因此它不跟踪哪些内存单元已被使用,也不查找未使用的内存块 delete只能用于释放指向常规new运算符分配的堆内存- 假设
char* buffer = new char[BUF],将其用于定位new运算符,最后delete[] buffer时,不会为使用定位new运算符创建的对象调用析构函数;而由于也不能使用delete删除这些对象,此时则需要显示地调用析构函数,以与创建顺序相反的顺序进行删除,且仅当所有对象都被销毁后,才能释放用于存储这些对象的缓冲区。
名称空间
假设名称空间和声明区域定义了相同的名称。如果试图使用 using 声明将名称空间的名称导入该声明区域,则这两个名称会发生冲突,从而出错;而如果使用 using 编译指令将该名称空间的名称导入该声明区域,则局部版本将隐藏名称空间版本。
可以给名称空间创建别名,用于简化对嵌套名称空间的使用:
1
2namespace MEF = myth::elements::fire;
using MEF::flame;名称空间指导原则:
- 使用在已命名的名称空间中声明的变量,而不是使用外部全局变量。
- 使用在已命名的名称空间中声明的变量,而不是使用静态全局变量。
- 如果开发了一个函数库或类库,将其放在一个名称空间中。
- 仅将编译指令
using作为一种将旧代码转换为使用名称空间的权宜之计。 - 不要在头文件中使用
using编译指令。首先,这样做掩盖了要让哪些名称可用;另外,包含头文件的顺序可能影响程序的行为。如果非要使用编译指令using,应将其放在所有预处理器编译指令#include之后。 - 导入名称时,首选使用作用域解析运算符或
using声明的方法。 - 对于
using声明,首选将其作用域设置为局部而不是全局。
类中的枚举
在类声明中声明的枚举的作用域为整个类,能被所有对象共享(类似静态类成员),例如:
1 | class Bakery |
这里 Months
只是一个符号名称,并不会创建类数据成员。在作用域为整个类的代码中遇到它时,编译器将用
12
来替换它。由于这里使用枚举只是为了创建符号常量,并不打算创建枚举类型的变量,因此不需要提供枚举名。
诸如
ios_base::fixed等标识符就是这样实现的,其中fixed是ios_base类中定义的典型的枚举量。
运算符重载的限制
- 重载后的运算符必须至少有一个操作数是用户定义的类型,这将防止用户为标准类型重载运算符;
- 使用运算符时不能违反运算符原来的句法规则,例如不能将求模运算符(%)重载成使用一个操作数;同样,也不能修改运算符的优先级;
- 不能创建新运算符;
- 不能重载以下运算符:
sizeof:sizeof运算符.:成员运算符.*:成员指针运算符:::作用域解析运算符?::条件运算符typeid:一个RTTI运算符const_cast:强制类型转换运算符dynamic_cast:强制类型转换运算符reinterpret_cast:强制类型转换运算符static_cast:强制类型转换运算符
- 以下运算符只能通过成员函数进行重载:
=:赋值运算符():函数调用运算符[]:下标运算符->:通过指针访问类成员的运算符
为什么需要友元函数?
一个很直接的场景是二目运算符的重载,其中一个操作数是自定义的对象,另一个是普通类型的情况,例如
A = B * 2.75。在这种情况下,如果以类成员函数的形式实现乘法运算符,将不具备交换律,诸如
A = 2.75 * B 这样的表达式就无法编译,因为 2.75
不是对象,编译器无法使用成员函数调用来替换该表达式。因此,最好是通过非成员函数来实现重载,但这会引发一个新的问题:非成员函数不能直接访问类的私有数据。那么友元函数就能很好地满足这种需求,相当于给
OOP 的封装性开了个后门。
当然,还有一种办法,就是先通过类成员函数实现正序的运算符函数,再通过普通函数调用前者以实现反序的运算符函数,此时这个函数不必是友元函数。例如:
1 | Time operator*(double m, const Time& t) |
类似地,重载 <<
运算符也是友元函数的一个常用场景。
乍一看,您可能会认为友元违反了OOP数据隐藏的原则,因为友元机制允许非成员函数访问私有数据。然而,这个观点太片面了。相反,应将友元函数看作类的扩展接口的组成部分。例如,从概念上看,
double乘以Time和Time乘以double是完全相同的。也就是说,前一个要求有友元函数,后一个使用成员函数,这是 C++ 句法的结果,而不是概念上的差别。通过使用友元函数和类方法,可以用同一个用户接口表达这两种操作。另外请记住,只有类声明可以决定哪一个函数是友元,因此类声明仍然控制了哪些函数可以访问私有数据。总之,类方法和友元只是表达类接口的两种不同机制。
一个 String 类的声明
1 | class String |
在构造函数中使用 new 时应注意的事项
- 如果在构造函数中使用 new 来初始化指针成员,则应在析构函数中使用 delete。
- new 和 delete 必须相互兼容。new 对应于 delete,new[ ] 对应于 delete[ ]。
- 如果有多个构造函数,则必须以相同的方式使用 new,要么都带中括号,要么都不带。因为只有一个析构函数,所有的构造函数都必须与它兼容。然而,可以在一个构造函数中使用 new 初始化指针, 而在另一个构造函数中将指针初始化为空(0 或 C++11 中的 nullptr),这是因为 delete(无论是带中括号还是不带中括号)可以用于空指针。
- 应定义一个复制构造函数,通过深度复制将一个对象初始化为另一个对象。具体地说,复制构造函数应分配足够的空间来存储复制的数据,并复制数据,而不仅仅是数据的地址。另外,还应该更新所有受影响的静态类成员。
- 应定义一个赋值运算符,通过深度复制将一个对象复制给另一个对象。具体地说,该方法应完成这些操作:检查自我赋值的情况,释放成员指针以前指向的内存,复制数据而不仅仅是数据的地址,并返回一个指向调用对象的引用。
伪私有方法
用于定义其对象不允许被复制的类,或禁用某些暂时不实现的方法,与其将来面对无法预料的运行故障,不如得到一个易于跟踪的编译错误。例如,将复制构造函数和赋值运算符定义为伪私有方法,避免自动生成的默认方法定义产生非预期的结果,同时其私有性保证了这些方法不能被广泛使用。
1 | class Queue |
C++11 提供了另一种禁用方法的方式——使用关键字 delete。
但依然需要注意:
- 当对象被按值传递(或返回)时,复制构造函数将被调用,因此应采用引用来传递对象。
- 复制构造函数还被用于创建其他的临时对象,因此要避免会创建临时对象的操作,例如重载加法运算符。
虚函数的工作原理
给每个对象添加一个隐藏成员:指向函数地址数组的指针。这种数组称为虚函数表(virtual function table, vtbl)。虚函数表中存储了类的所有虚函数的地址。例如,基类对象包含一个指针,该指针指向基类中所有虚函数的地址表。派生类对象将包含一个指向自己地址表的指针。如果派生类提供了虚函数的新定义,该虚函数表将保存新函数的地址;如果派生类没有重新定义虚函数,则保存函数原始版本的地 址。如果派生类定义了新的虚函数,则该函数的地址也将被添加到 vtbl 中。调用虚函数时,程序将查看存储在对象中的 vtbl 地址,然后转向相应的函数地址表。如果使用类声明中定义的第一个虚函数,则程序将使用数组中的第一个函数地址,并执行具有该地址的函数。如果使用类声明中的第三个虚函数,程序将使用地址为数组中第三个元素的函数。
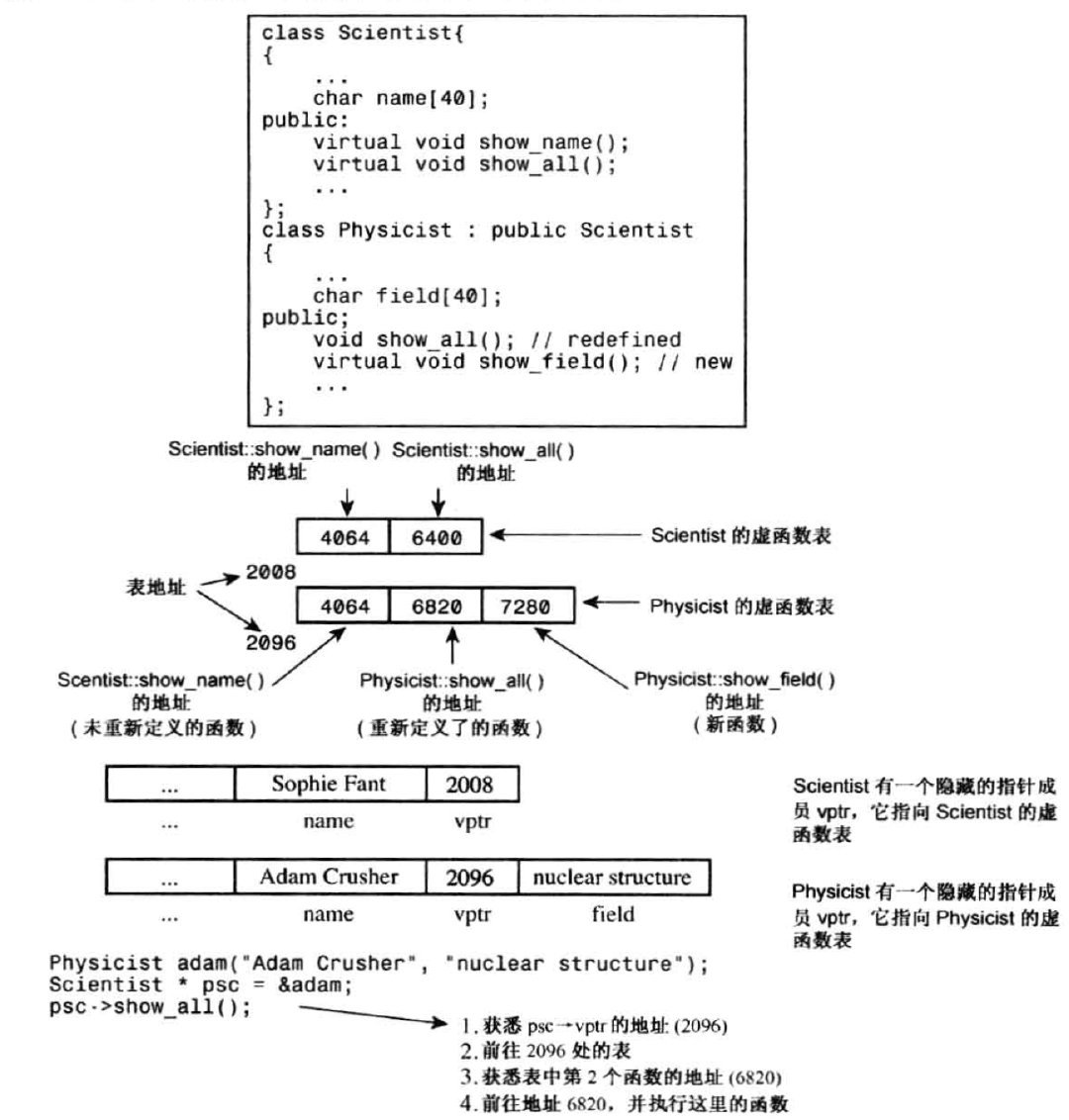
使用虚函数时,在内存和执行速度方面有一定的成本,包括:
- 每个对象都将增大,增大量为存储地址的空间;
- 对于每个类,编译器都创建一个虚函数地址表(数组);
- 对于每个函数调用,都需要执行一项额外的操作,即到表中查找地址。
有关虚函数的注意事项
- 在基类方法的声明中使用关键字 virtual 可使该方法在基类以及所有的派生类(包括从派生类派生出来的类)中是虚的。
- 如果使用指向对象的引用或指针来调用虚方法,程序将使用为对象类型定义的方法,而不使用为引用或指针类型定义的方法。这称为动态联编或晚期联编,从而使得基类指针或引用可以指向派生类对象。
- 如果定义的类将被用作基类,则应将那些要在派生类中重新定义的类方法声明为虚的。
- 构造函数不能是虚函数,派生类不继承基类的构造函数。创建派生类对象时,将调用派生类的构造函数,而不是基类的构造函数,然后派生类的构造函数使用成员初始化列表来调用基类构造函数。如果派生类构造函数没有显式调用基类构造函数,将使用基类的默认构造函数。(C++11 新增了一种继承构造函数的机制,但默认仍不继承)
- 析构函数应当是虚函数,除非类不用做基类,但也不能继承。delete 语句先调用派生类的析构函数,然后调用基类的析构函数。即使基类不需要显式析构函数提供服务,也不应依赖于默认构造函数,而应提供虚析构函数,即使它不执行任何操作。
- 友元不能是虚函数,因为友元不是类成员,而只有成员才能是虚函数。如果由于这个原因引起了设计问题,可以通过让友元函数使用虚成员函数来解决。
- 如果派生类没有重新定义函数,将使用该函数的基类版本。如果派生类位于派生链中,则将使用最新的虚函数版本,例外的情况是基类版本是隐藏的。
- 如果重新定义继承的方法,应确保与原来的原型(参数列表)完全相同,否则将隐藏同名的基类方法,而不会形成重载。但如果返回类型是基类引用或指针,则可以修改为指向派生类的引用或指针,这种特性被称为返回类型协变(covariance of return type),因为允许返回类型随类类型的变化而变化。
- 如果基类声明被重载了,则应在派生类中重新定义所有的基类版本。如果只重新定义一个版本,则另外两个版本将被隐藏,派生类对象将无法使用它们。注意,如果不需要修改,则新定义可只调用基类版本。
保护访问控制:protected
- 对于类数据成员,最好不要使用保护访问控制,而是采用私有访问控制,并通过基类方法使派生类能够访问基类数据。
- 对于成员函数来说,保护访问控制很有用,它让派生类能够访问公众不能使用的内部函数。
继承和动态内存分配
如果基类使用动态内存分配(new/delete),并重新定义赋值和赋值构造函数,这将怎样影响派生类的实现呢?根据派生类的属性分两种情况讨论。
派生类不使用 new
不需要为派生类定义显式析构函数、复制构造函数和赋值运算符,因为它们各自的默认实现将自动调用基类的对应方法,无论其在基类中是默认的还是显式定义的。
派生类使用 new
必须为派生类定义显式析构函数、复制构造函数和赋值运算符。
析构函数:
释放自身管理的内存即可,基类的析构函数会被自动调用。
复制构造函数:
除了复制自己的数据,还必须显式调用基类的复制构造函数。可以在初始化列表中将派生类引用传递给基类的复制构造函数,因为基类引用可以指向派生类型,并使用其基类部分来构造新对象的基类部分。
1
Derived::Derived(const Derived& d) : Base(d) { ... }
赋值运算符:
除了复制自己的数据,还必须显式调用基类的赋值运算符。但只能以函数表示法调用,这样才能使用作用域解析运算符,否则如果直接使用
=赋值,编译器将调用派生类的赋值运算符,从而形成递归。1
2
3
4
5
6
7Derived& Derived::operator=(const Derived& d)
{
if (this == &d)
return *this;
Base::operator=(d); // copy base portion
...
}
派生类如何使用基类的友元
作为派生类的友元,该函数可以访问派生类自己的数据,但不能直接访问基类部分的数据,因此需要将派生类对象强制转换为基类类型,以便匹配原型时能够使用基类的友元函数,否则将导致递归调用。
1 | std::ostream& operator<<(std::ostream& os, const Derived& d) |
类函数总结
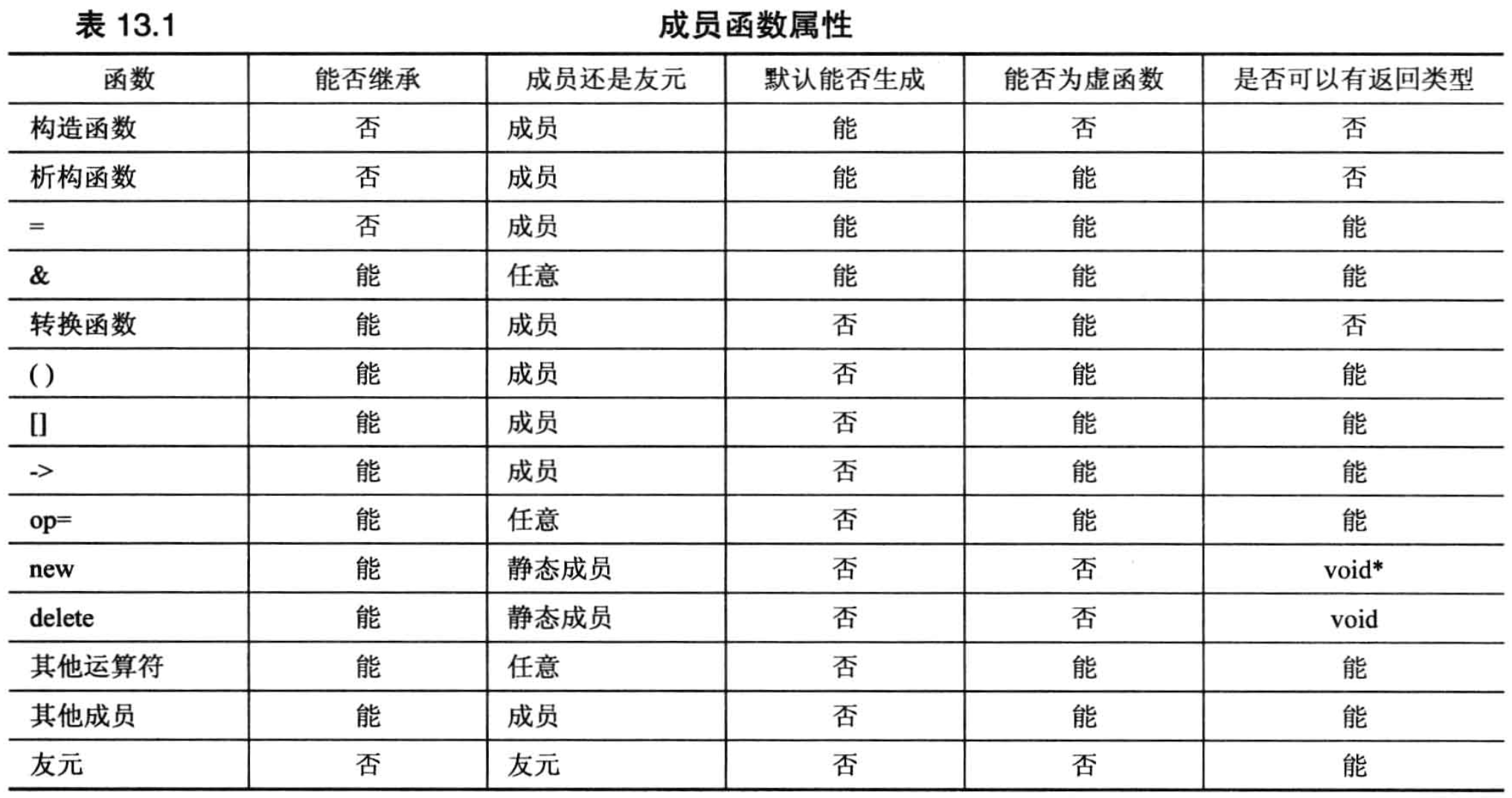
其中 op= 表示诸如 +=、*= 等格式的赋值运算符。注意,op= 运算符的特征与“其他运算符”类别并没有区别,单独列出 op= 旨在指出这些运算符与 = 运算符的行为是不同的。
接口和实现
- 使用公有继承(is-a 关系)时,类可以继承接口,可能还有实现(基类的纯虚函数提供接口,但不提供实现)。
- 使用组合(has-a 关系)时,类可以获得实现,但不能获得接口。
通常,包含、私有继承和保护继承用于实现 has-a 关系,即新的类将包含另一个类的对象。
包含与私有继承
使用区别:
- 包含提供显示命名的对象成员,而私有继承提供无名称的子对象成员;
- 包含使用成员名来标识初始化列表中的构造函数,而私有继承使用类名;
- 包含使用对象名来调用方法,而私有继承使用类名和作用域解析运算符;
- 包含可以直接访问对象成员,而私有继承通过强制类型转换将自身转换为基类对象;
包含优于私有继承的地方:
- 易于理解
- 继承会引起很多问题,尤其是多继承,例如多个基类拥有同名方法或公共祖先;
- 包含能够包括多个同类的子对象,而继承只能使用一个这样的对象;
私有继承优于包含的地方:
- 假设类中存在保护成员,则该成员在派生类中可用,但在所包含的类中无法访问;
- 派生类可以重新定义虚函数,但包含类不能。使用私有继承,重新定义的函数将只能在类中使用,而不是公有的。
通常,应使用包含来建立 has-a 关系;如果新类需要访问原有类的保护成员,或需要重新定义虚函数,则应使用私有继承。
公有、私有和保护继承
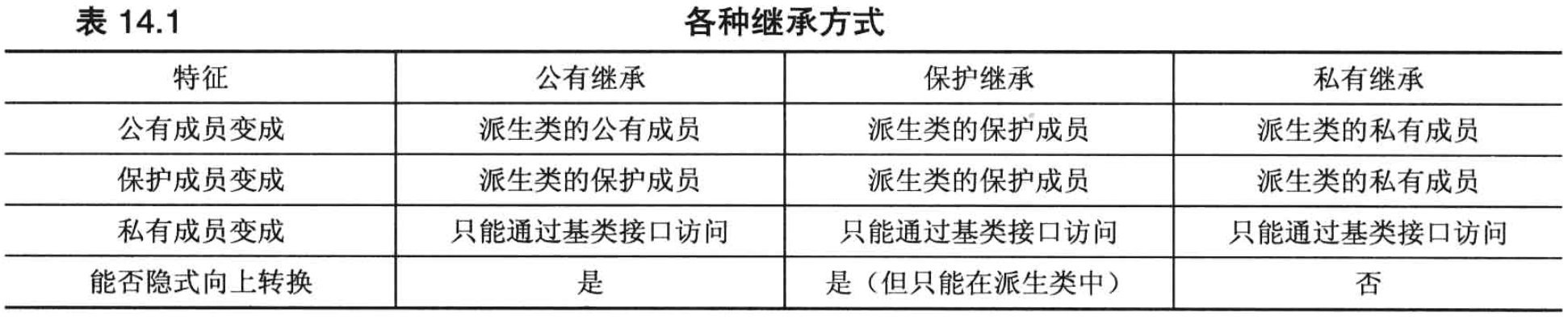
使用 using 重新定义访问权限
使用 using
声明来指出派生类可以使用特定的基类成员(必须是公有成员),即使采用的是私有派生。例如:
1 | class Student : private std::string, private std::valarray<double> |
这使得 valarray<double>::min() 和
std::valarray<double>::max() 在类外可用,就像它们是
Student 的公有方法一样。
注意:using
声明只使用成员名(没有圆括号、函数特征标和返回类型),且只适用于继承,而不适用于包含。
两种方法实现变长数组模板
使用动态数组和构造函数参数来提供元素数目
- 优点:更通用,数组大小作为类成员而不是硬编码,这样可以将一种大小的数组赋给另一种大小的数组,也可以创建允许数组大小可变的类;
- 缺点:通过 new 和 delete 管理堆内存,性能较常规数组差;
1
2
3
4
5
6
7
8
9
10
11
12
13template <typename T>
class Array
{
private:
enum {SIZE = 10}; // default size
int size;
T* items;
public:
explicit Array(int sz = SIZE);
Array(const Array& arr);
~Array() { delete[] items; }
...
}使用非类型(表达式)模板参数来提供常规数组的大小
- 优点:为自动变量维护内存栈,执行速度更快,尤其是很多小型数组的情况;
- 缺点:每种数组大小都将生成自己的类声明;
- 表达式参数的限制:
- 表达式参数只能是整型、枚举、引用或指针
- 模板代码不能修改表达式参数的值,也不能使用参数的地址
- 实例化模板时,用作表达式参数的值必须是常量表达式
1
2
3
4
5
6
7
8
9
10template <typename T, int n>
class Array
{
private:
T arr[n];
public:
Array() {};
explicit Array(const T& v);
....
}
异常
throw语句会释放栈中的自动存储型变量;- 程序进行栈解退,回到第一个能够捕获该异常的
try-catch组合处; - 引发异常时编译器总是创建一个临时拷贝,即使异常规范和
catch块中指定的是引用,这是因为此时该异常对象可能已经析构; - 使用引用的另一个原因是基类引用可以指向派生类对象:假设有一组通过继承关联起来的异常类型,则只需列出一个基类引用,它将与任何派生类对象匹配;
- 因此,
catch块的排列顺序应与派生顺序相反,即将捕获位于继承层次结构最下面的异常类的catch语句放在最前面,将捕获基类异常的catch语句放在最后面。 - 当然,也可以创建捕获对象而不是引用的程序:在
catch语句中使用基类对象时,将捕获所有的派生类对象,但派生特性将被剥去,因此将使用虚方法的基类版本。
stdexcept 异常类
logic_error:可以通过编程修复的逻辑错误domain_error:参数取值不在定义域内invalid_argument:非法参数length_error:没有足够的空间来执行所需的操作out_of_bounds:索引错误
runtime_error:可能在运行期间发生但难以预计和防范的错误overflow_error:计算结果超过某种类型能够表示的最大数量级(上溢)underflow_error:计算结果小于浮点类型可以表示的最小非零值(下溢)range_error:计算结果不在函数允许的范围之内,但没有发生上溢或下溢错误
类型转换
dynamic_cast:只允许向上转换,否则返回空指针或抛错(引用)static_cast:只要两个方向中有一方可以隐式转换就是合法的,因此可以向下转换(但不安全)const_cast:删除指针或引用的 const 限定符,但如果指向的内容本身是常量,则依然无法修改reinterpret_cast:- 依赖底层实现,不可移植(e.g. 不同系统可能按不同顺序存储多字节整型)
- 可以将指针类型转换为足以存储指针表示的整型,但不能将指针转换为更小的整型或浮点型
- 不能将函数指针转换为数据指针,反之亦然
- 不允许删除指针或引用的 const 限定符
智能指针
使用 new 分配内存时,才能使用 auto_ptr 和
shared_ptr,使用 new[]
分配内存时,不能使用它们,但可以使用 unique_ptr。
不使用 new 分配内存时,不能使用 auto_ptr 或
shared_ptr;不使用 new 或 new[]
分配内存时,不能使用 unique_ptr。
为什么要使用迭代器?
模板使得算法独立于存储的数据类型,而迭代器使算法独立于使用的容器类型。
如何为两种不同数据表示(e.g. 数组和链表)实现 find
函数?如何推广这种方法?
尽管可以用模板将 find
算法推广到任意元素类型的数组(或链表),但这种算法仍然与一种特定的数据结构关联在一起:一个使用数组索引来遍历元素,另一个则将指针指向下一个节点。但从广义上说,这两种算法是相同的:将值依次与容器中的每个值进行比较,直到找到匹配的为止。
泛型编程旨在使用同一个 find
函数来处理数组、链表或任何其他容器类型。即函数不仅独立于容器中存储的数据类型,而且独立于容器本身的数据结构。模板提供了存储在容器中的数据类型的通用表示,因此还需要遍历容器中的值的通用表示,迭代器正是这样的通用表示。
具体实现上:
- 对于数组,常规指针就能满足迭代器的要求;
- 对于链表,可以定义一个迭代器类,其中定义了运算符
*和++,分别用于封装解引用和移动到下一个位置的操作。
这样,二者的 find
函数就变得几乎相同,仅剩的差别在于如何表示已到达最后一个值。数组使用超尾迭代器,而链表使用存储在最后一个节点中的空值。例如,可以要求链表的最后一个元素后面还有一个额外的元素,即和数组一样拥有超尾元素,并在迭代器到达超尾位置时结束搜索。由此,这两个函数就成为了完全相同的算法。注意,增加超尾元素后,对迭代器的要求变成了对容器类的要求。
STL 正是通过为每个类定义适当的迭代器,并以统一的风格来设计类,从而能够对内部表示绝然不同的容器,编写相同的代码。
总结一下 STL 的基本思想。处理容器的算法应尽可能用通用的术语来表达算法,使之独立于数据类型和容器类型。为使通用算法能够适用于具体情况,应定义能够满足算法需求的迭代器,并把要求加到容器设计上。即基于算法的要求,设计基本迭代器的特征和容器特征。
函数符(functor)
函数符是可以以函数方式与 ()
结合使用的任意对象,包括函数名、指向函数的指针和重载了 ()
运算符的类对象。例如:
1 | class Linear |
STL 定义的一些函数符概念:
- 生成器(generator)是不用参数就可以调用的函数符;
- 一元函数(unary function)是用一个参数可以调用的函数符;
- 二元函数(binary function)是用两个参数可以调用的函数符;
- 返回 bool 值的一元函数是谓词(predicate);
- 返回 bool 值的二元函数是二元谓词(binary predicate)。
list 模板有一个将谓词作为参数的 remove_if()
成员,该函数将谓词应用于区间中的每个元素,如果谓词返回
true,则删除这些元素。例如:
1 | bool tooBig(int n) { return n > 100; } |
假设要删除另一个链表中所有大于 200
的值,如果能将取舍值作为第二个参数传递给
tooBig(),则可以使用不同的值调用该函数,但谓词只能有一个参数。此时可以使用类函数符,通过类成员而不是函数参数来传递额外的信息:
1 | template<class T> |
特殊的成员函数
- 在没有提供任何参数的情况下,将调用默认构造函数。如果您没有给类定义任何构造函数,编译器将提供一个默认构造函数。这种版本的默认构造函数被称为默认的默认构造函数。对于使用内置类型的成员,默认的默认构造函数不对其进行初始化;对于属于类对象的成员,则调用其默认构造函数。
- 另外,如果您没有提供复制构造函数,而代码又需要使用它,编译器将提供一个默认的复制构造函数;如果您没有提供移动构造函数,而代码又需要使用它,编译器将提供一个默认的移动构造函数。
- 最后,如果您没有提供析构函数,编译器将提供一个。
- 对于前面描述的情况,有一些例外。如果您提供了析构函数、复制构造函数或复制赋值运算符,编译器将不会自动提供移动构造函数和移动赋值运算符;如果您提供了移动构造函数或移动赋值运算符,编译器将不会自动提供复制构造函数和复制赋值运算符;如果您提供了移动构造函数,编译器将不会自动提供默认构造函数。
- 另外,默认的移动构造函数和移动赋值运算符的工作方式与复制版本类似:执行逐成员初始化并复制内置类型。如果成员是类对象,将使用相应类的构造函数和赋值运算符,就像参数为右值一样。如果定义了移动构造函数和移动赋值运算符,这将调用它们;否则将调用复制构造函数和复制赋值运算符。
default 和 delete
关键字 default 只能用于 6 个特殊成员函数,但
delete 可用于任何成员函数。delete
的一种可能用法是禁止特定的转换。例如有如下代码:
1 | class Someclass |
如果没有禁止 redo(int) ,int 值 5 将被提升为
5.0,进而执行方法 redo(double)。使用关键字
delete 后,编译器将这种调用视为编译错误。
继承构造函数
通过 using
声明,让派生类继承基类的所有构造函数(默认构造函数、复制构造函数和移动构造函数除外),但不会使用与派生类构造函数的特征标匹配的构造函数:
1 | class BS |
由于没有构造函数 DR(int, double),因此创建
DR 对象 o3 时,将使用继承而来的
BS(int, double)。请注意,继承的基类构造函数只初始化基类成员;如果还要初始化派生类成员,则应使用成员列表初始化语法:
1 | DR(int i, int k, double x) : j(i), BS(k, x) {} |
override 和 final
假设基类声明了一个虚方法,而您决定在派生类中提供不同的版本,这将覆盖旧版本。但如果特征标不匹配,将隐藏而不是覆盖旧版本:
1 | class Action |
由于类 Bingo 定义的是 f(char* ch) 而不是
f(char ch),将对 Bingo 对象隐藏
f(char ch)。
在 C++11 中,可使用虚说明符 override
指出您要覆盖一个虚函数:
1 | virtual void f(char *ch) const override { std::cout << val() << ch << "!\n"; } |
如果声明与基类方法不匹配,编译器将视为错误。
如果想禁止派生类覆盖特定的虚方法,可以使用 final:
1 | virtual void f(char ch) const final { std::cout << val() << ch << "\n"; } |
这将禁止 Action 的派生类重新定义函数
f()。
包装器 function 及模板的低效性
函数名、函数指针、函数对象或有名称的 lambda 表达式都是可调用的类型(callable type)。
如果有一个模板的参数表示可调用类型,那么传入上述不同类型将导致模板多次实例化,因而效率低下,而且会增加可执行代码的大小。
头文件 functional 中的模板 function 可以解决上述问题,它从调用特征标的角度定义了一个对象,可用于包装调用特征标相同的函数指针、函数对象或 lambda 表达式。例如:
1 | std::function<double(char, int)> fdci; |
可以将接受一个 char 参数和一个 int 参数,并返回一个 double 值的任何可调用类型赋给它。
使用 function 类型后,模板只会实例化一次。